Looking at the insights from our previous article, the Model Context Protocol (MCP) is already finding its place in the digital landscape. It brings clear benefits for teams that want to integrate it, and its value is hard to overstate. The fact that world-renowned companies are already relying on MCP only adds to its momentum.
So, what does this mean for developers? It’s time to start working with it.
At Keenethics, we’re exploring this concept closely and testing it in real projects. Drawing on these hands-on experiences, we’ll walk through how the protocol works, what’s under the hood, and what challenges developers need to keep in mind.
The architecture of MCP
To understand how MCP works in practice, it helps to look at its basic architecture. The protocol defines clear roles for each participant, so developers know exactly how data and requests move through the system. At its simplest, MCP is built around three components: the host, the client, and the server.
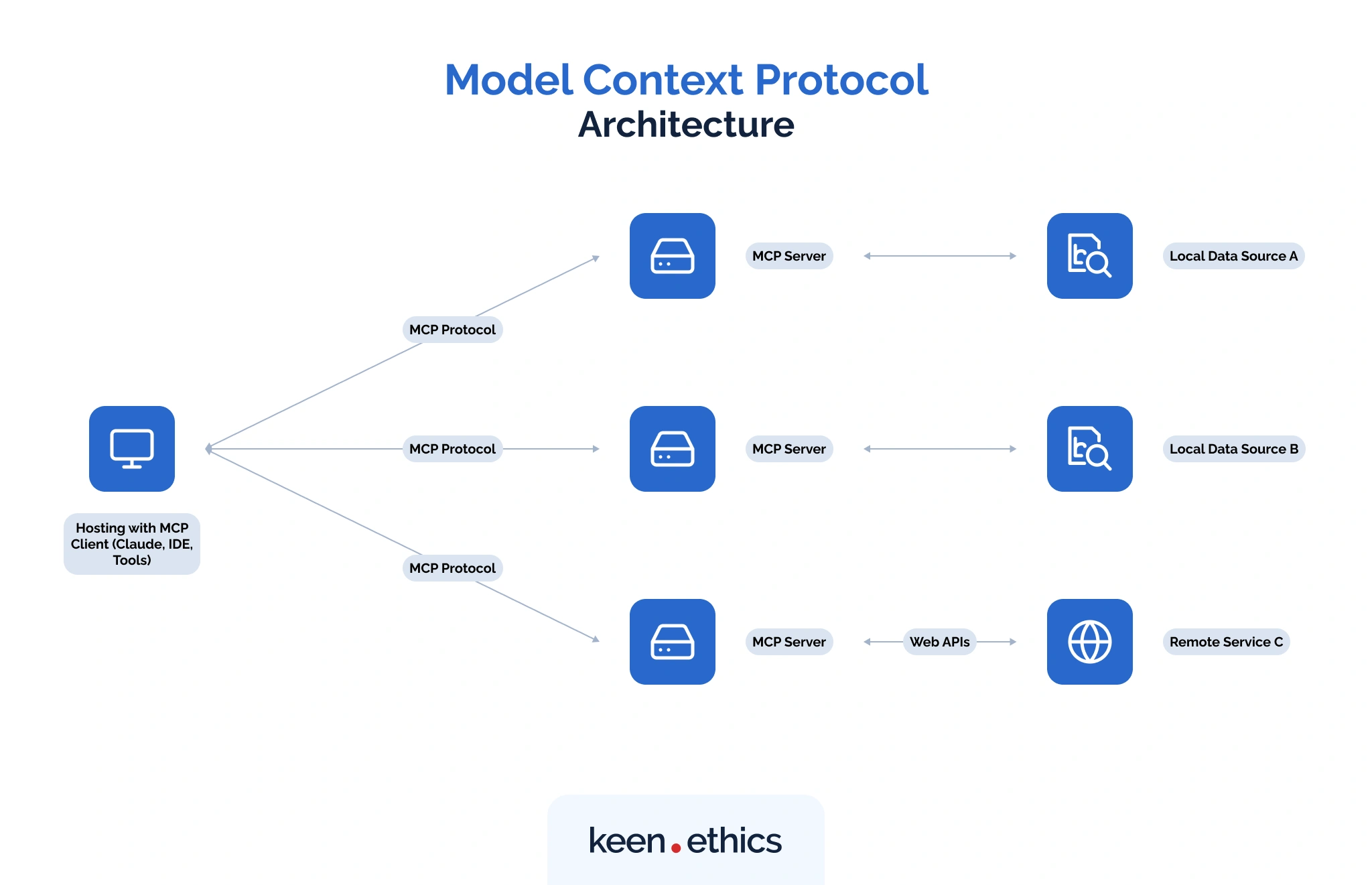
MCP host
The host is the environment where an LLM runs and where MCP interactions are coordinated. It acts as the “runtime container” that manages connections, enforces permissions, and ensures that tools exposed by MCP servers are available to the model in a controlled way.
In many cases, the host is part of an AI application itself (e.g., Claude Desktop, ChatGPT client). Its main role is to give the model a secure and consistent way to reach external tools without bypassing defined rules.
MCP client
The client is the bridge between the host and one or more MCP servers. It handles the actual communication using JSON-RPC messages and transports like STDIO, SSE, or streamable HTTP.
A client is responsible for:
- Sending initialization requests and tool calls to the server.
- Receiving responses or streamed events back.
- Managing states such as session IDs or event histories (in remote setups).
Because the client sits in the middle, it’s also where developers configure which servers are available, what credentials are used, and how requests are routed. In practice, the client decides whether a model can talk to a local MCP server on the filesystem, a remote server over HTTP, or a mix of both.
MCP server
The server is where the actual capabilities live. It exposes the functions and resources that a model can call through the client, making it the backbone of MCP.
By their nature, servers can run locally or remotely. Local servers, connected via STDIO, are fast and require no authentication, though they depend on the client’s host. Remote servers, connected over SSE or Streamable HTTP, are better suited for scaling but come with trade-offs like authentication requirements, connection management, and rate limiting (we’ll look at these setups in more detail shortly).
One real-world example is PayPal’s MCP server, which allows AI agents to create invoices, issue refunds, and generate payment links through standardized tool calls. This setup shows that MCP servers can deliver real functionality, keeping permissions and compliance tightly controlled.
In practice, a server could provide a database query tool, an API wrapper, or access to a document repository. What matters is that it defines the concrete capabilities available to the model.
How does MCP work
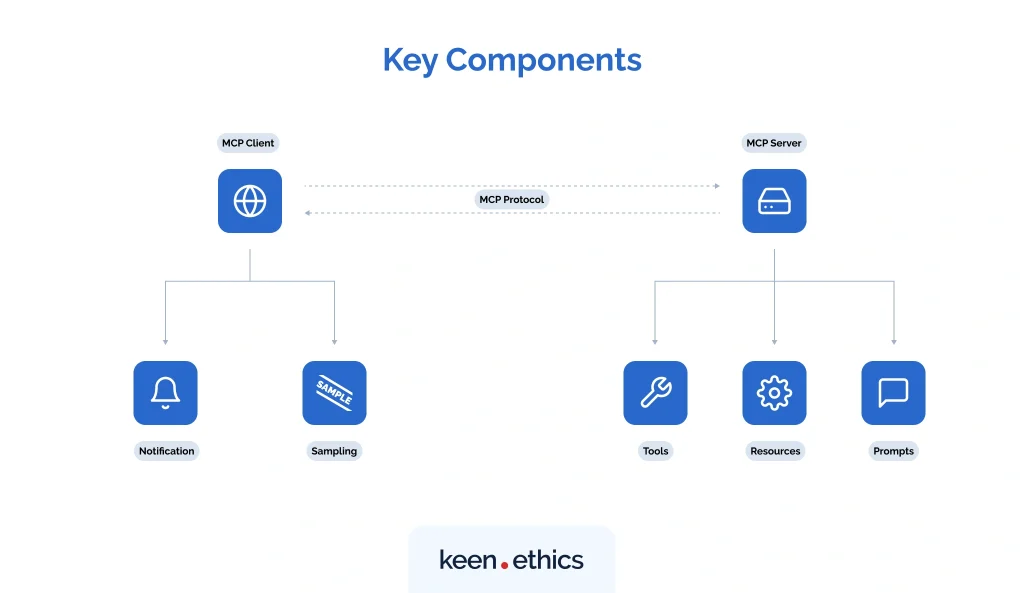
Beyond its architecture, MCP is defined by a set of building blocks that make it practical for development. Together, they form the contract between client, server, and host, expressed through JSON-RPC messages and enforced by the protocol itself.
The core elements are:
- Tools
- Resources
- Prompts
- Sampling & Roots (newer features)
Tools are the functional units that a model can call. They can query a database, hit an API endpoint, or execute a script. Because tools accept input directly from the LLM, they require careful configuration to avoid unintended consequences.
“When you expose a tool that takes SQL queries as input, you have to make sure the model can’t generate destructive commands. A careless setup could let the model produce something like a DELETE statement that wipes data.” — Alexander Shcherbatov, Keenethics developer
Resources define how external data is accessed and reused. Rather than embedding a file, document, or API response directly into a prompt, a resource gives the model a structured way to retrieve that information when needed. This approach keeps data access predictable and easier to control across environments.
Prompts are reusable templates that guide how models request and deliver information. They provide a stable phrasing for recurring tasks, which improves response quality and makes it easier to review or adjust how the model is instructed.
It’s worth noting that prompts in MCP can be structured forms that gather values and build the final instruction automatically. For example, Claude’s MCP implementation allows a user to fill in delivery details through a form:
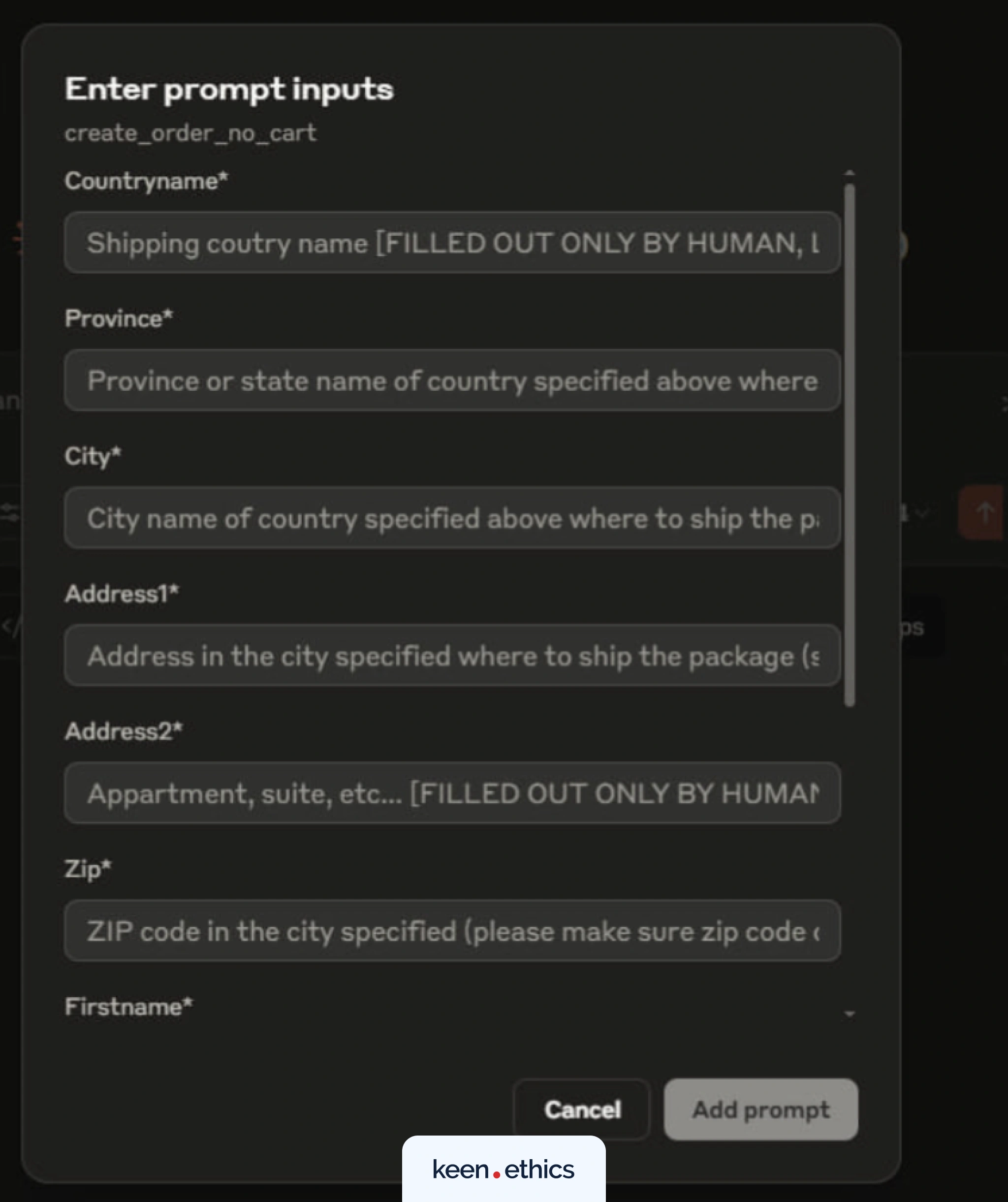
For the form above, the prompt is as follows:

The variables inside the brackets are replaced with user-provided values, and the complete prompt is then passed to the model. This approach ensures consistency, reduces ambiguity, and makes prompts easier to maintain as part of an MCP server.
Sampling allows an MCP server to request the host/client to perform an LLM inference (with the host’s models, credentials, and policies), optionally streaming partial results. This enables server logic to interleave tool execution with model calls without embedding a model.
Roots define the boundaries of filesystem access that an MCP server is allowed to use. Servers must confine any file URIs and operations to the declared roots, honoring updates and preventing traversal outside those directories.
Transports in MCP
Just like tools, resources, and prompts define what an LLM can do, the transport layer defines how that data travels between client and server. Each option comes with its own strengths, limitations, and use cases, and choosing the right one often depends on the environment where MCP is deployed.
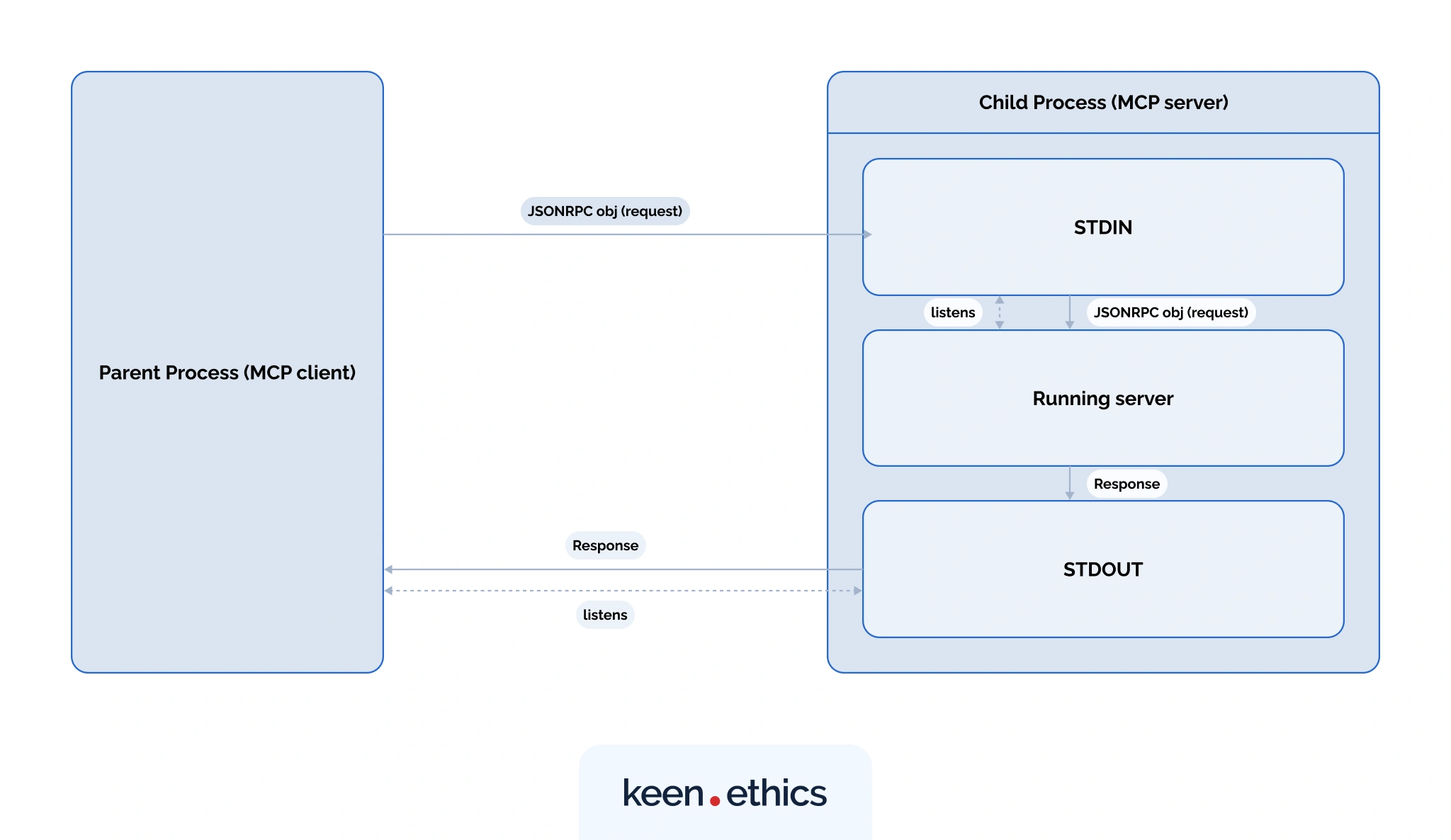
STDIO
In STDIO, the client and server communicate directly through the server process’s standard input and output streams. The client launches the server as a child process and writes JSON-RPC requests into its STDIN, such as:
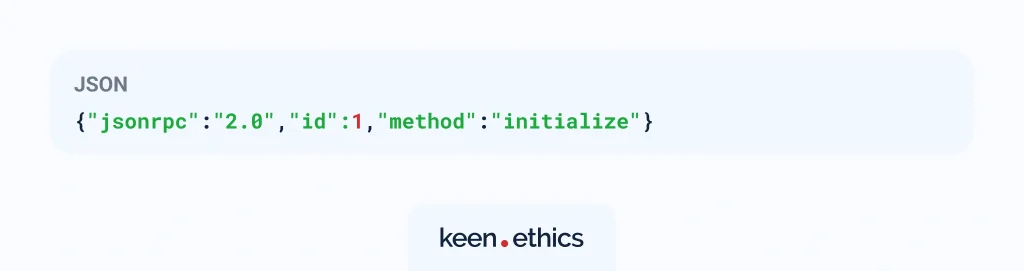
Each request is separated by a newline \n, the server processes it, and then writes the response to STDOUT, which the client continuously listens to.
This setup has two major advantages: it eliminates network latency and requires no authentication, since everything runs locally. As a result, STDIO works best for local tasks like shell scripts, CLI tools, or desktop apps. But here, performance and reliability are tied to the client’s host.
If the host dies, the STDIO pipes close, well-implemented servers detect EOF/write errors and exit. Otherwise the server may linger as an orphan, but the client still loses access because the connection is gone.
“The launched local MCP server is not reusable among clients. For each new client, a separate process running a new MCP server needs to be launched.” — Alexander Shcherbatov, Keenethics developer
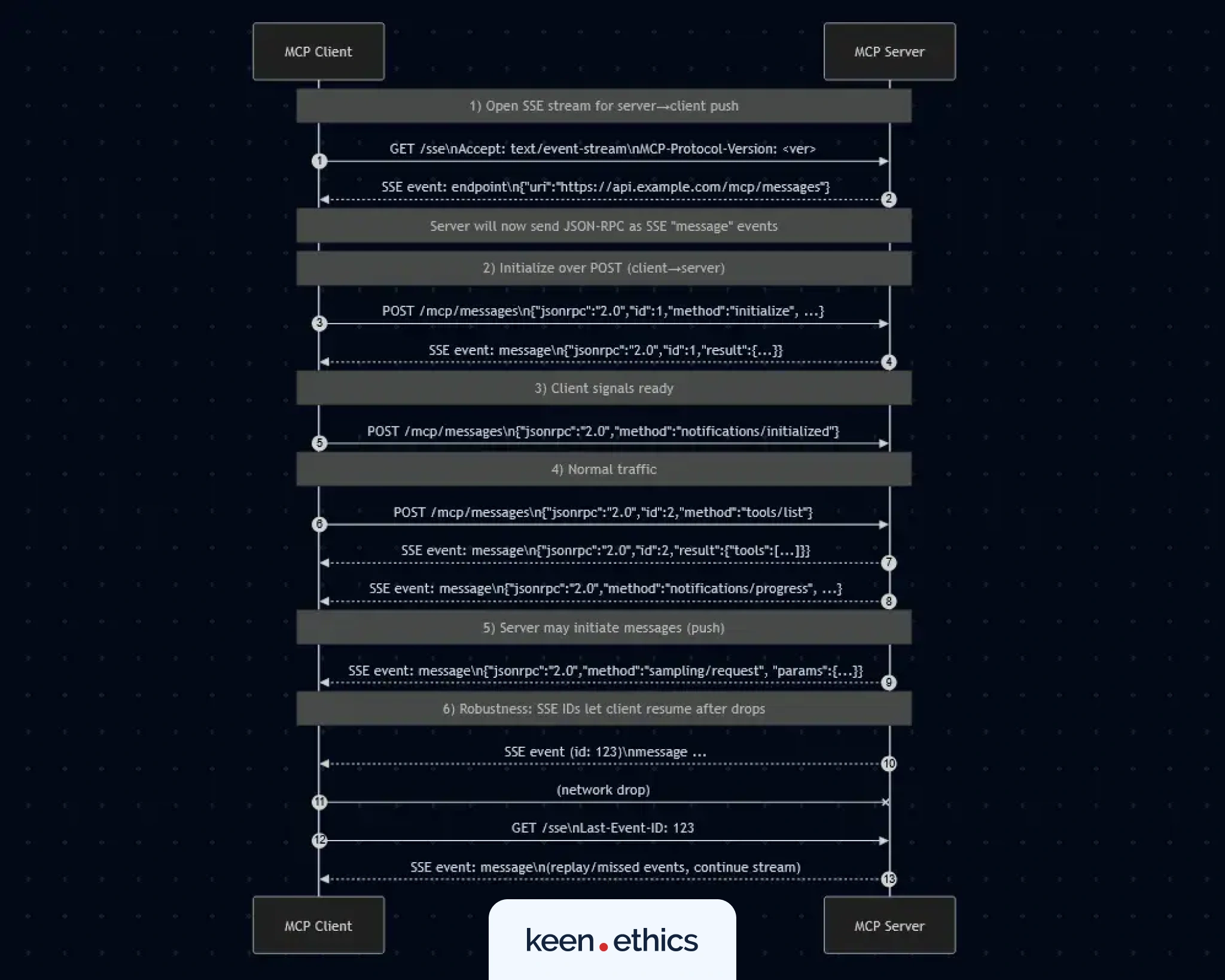
Server-Sent Events (SSE)
SSE was the first transport to support remote MCP communication. Unlike STDIO, the client and server don’t share the same host. Instead, they keep a persistent HTTP connection alive, streaming responses back in real time. The process works step by step:
- The client requests the MCP server’s /sse endpoint.
- The server creates a unique session ID.
- That ID is assigned to the connection.
- The server responds with an SSE event, which contains an endpoint, where the client can send messages (usually `/messages`) and a unique session ID.
- The client includes this ID in its headers or cookies with every request, so the server can route messages to the correct session.
Once initialized, the client sends HTTP POST requests to the /messages endpoint, and the server responds with JSON-RPC objects streamed over SSE. This enables chunked responses, real-time notifications, and automatic retries. If a connection drops, the client reconnects with the last event ID, and the server can replay events if it stores history.
“With SSE-based servers, every new client keeps a persistent connection open. At high volumes, those connections can quickly drain server resources.” — Alexander Shcherbatov, Keenethics developer.
For developers who want to explore further, the full example MCP server implementation can be found here.
SSE is most relevant for remote servers that need real-time, one-way updates, like sending live data streams or progress notifications from a cloud service to the client. It’s less convenient for large-scale or multi-client deployments, which is why it has largely been replaced by Streamable HTTP in modern setups.
Streamable HTTP
Streamable HTTP is the successor to SSE and is now the recommended default transport. It simplifies the design by using a single endpoint (commonly /mcp) instead of two, and supports both immediate responses (application/json) for short tasks and streaming responses (text/event-stream) for longer ones.
The crucial detail is that the MCP client must be able to handle both modes. It needs to parse standard JSON for synchronous replies and process streaming events as they arrive, switching seamlessly based on the Content-Type header the server sets.
This flexibility makes Streamable HTTP the best fit for hybrid and production environments. It scales well for multi-client setups, works cleanly in cloud deployments, and still supports local development.

Security challenges that come with MCP’s growing influence
As MCP adoption accelerates, so do the security considerations. By design, the protocol gives language models access to powerful tools and data sources, which makes its guardrails just as important as its functionality. If these guardrails are weak, a misconfigured MCP server can become a serious vulnerability.
Prompt injection
The most immediate risk is prompt injection, where malicious or manipulated input tricks the model into calling tools in unintended ways. In a classic scenario, a model might be convinced to forward sensitive tokens to an external API or execute a sequence of commands beyond its intended scope.
With MCP, this danger is amplified because the model can trigger real actions across servers and APIs. Mitigations here require strict validation of tool inputs, whitelisting safe operations, and clear permission boundaries.
Token theft and leakage
Because MCP servers often connect to downstream APIs and enterprise systems, they rely on tokens and credentials. Poorly implemented servers can expose these secrets, either through overly verbose error logs or by letting models output them directly. Proper secret management, encrypted storage, and redaction of sensitive values in responses are critical to making MCP safe in production.
Windows registry rules and local policies
For desktop clients, Windows environments add their own layer of security concerns. MCP servers running locally may need to register within the system, and misconfigurations in registry rules could expose unexpected endpoints or allow privilege escalation. This area is still maturing, but it highlights the need for OS-level policies that tightly control which MCP servers can be launched and what resources they can touch.
Remote servers and OAuth patterns
When MCP servers are remote (deployed on Cloudflare Workers, Copilot Studio, or similar platforms), identity becomes a central issue. OAuth is the common standard, but implementation matters. Overly broad scopes or poorly managed refresh tokens create attack surfaces that malicious actors can exploit.
The safest implementations lean on narrow scopes, short-lived tokens, and explicit consent prompts before a model gains access to sensitive data.
Rate limiting
MCP servers that expose APIs remain vulnerable to denial-of-service and brute-force attacks if they don’t enforce request quotas. Without controls, a small number of clients can flood a server with requests and degrade availability.
Beyond simple per-client throttles, operators often introduce sliding-window counters, token-bucket algorithms, or request prioritization to protect critical endpoints. Rate limiting should also tie into your authentication model so that compromised or misused tokens can be quickly revoked.
GraphQL query depth
When an MCP server is backed by GraphQL (for example, with an Apollo implementation), unbounded queries pose a different risk. Attackers can craft recursive or deeply nested queries that trigger exponential computation, consuming CPU and memory even with relatively few requests. Practical defenses include enforcing query depth limits, applying query cost analysis, and using circuit breakers.
MCP is only getting started
As you can see, the Model Context Protocol is not a finished product you can plug in and forget. It is a living specification that pushes developers to think carefully about how models should talk to tools, how data boundaries are enforced, and how transport layers behave under real load. The reward for that effort is a foundation that makes multi-model and multi-platform AI systems much easier to build and maintain.
For practitioners, the next step is to prototype, contribute, and stress-test. The protocol will continue to mature through real-world use, and those who engage early will be best positioned to shape its evolution. At the same time, other approaches remain part of the field, and if you’d like to explore them in detail, you can check our article on LLM tooling.
Contact us to find out more about our software development services!