When teams start experimenting with large language models, the first results can be impressive (but also limited). Out of the box, an LLM can only work with what it has memorized during training. It won’t know your company’s internal data, it can’t trigger actions in your systems, and it struggles with tasks that require real-time updates. To make AI truly useful in business settings, you need a way to connect it with the tools, APIs, and knowledge sources you already rely on.
MCP is one answer to that. It tackles the hardest problems developers face: how to make integrations portable across providers, how to standardize context exchange, and how to keep permissions transparent and enforceable. Those benefits explain the excitement around MCP, but it’s not the only path available.
In reality, there are several ways to extend and integrate LLMs, each with its own trade-offs. Some shine when you need speed, others when you need tight control, and some when all you want is knowledge grounding.
In this article, we’ll walk through those options so you can make deliberate choices. And who knows, by the end, you may discover the exact approach you’ve been searching for.
Understanding LLM tooling options
LLM integration has already gone through several iterations. We’ve seen the rise of simple API calls, then function calling, then plugins, and now protocols like MCP. Each step adds new capabilities but also new responsibilities. To understand where MCP fits, let’s examine the different tooling models side by side.
Direct API integrations
The most common way teams start extending an LLM is the most straightforward. You take the model’s output, call an external API from your backend, and feed the result back into the conversation. If the model suggests “check the weather in Berlin,” your code hits a weather API, grabs the JSON, and returns a nicely formatted answer to the user.
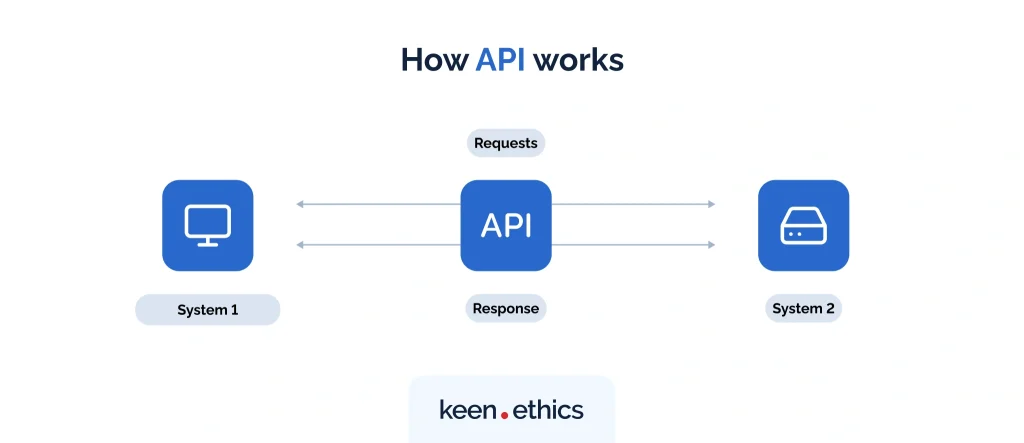
For early projects and prototypes, this approach is hard to beat. You can ship quickly, you don’t need to learn a new protocol, and you have full control over how requests are sent, authenticated, and logged. Developers often wire up a few endpoints directly in their application layer and get something working in days rather than weeks.
The trade-offs only become obvious as the project grows. Each LLM provider implements its own flavor of function calling, so if you want the same tool to run in multiple environments — say, a customer-facing chatbot in ChatGPT and a code helper in Claude — you end up rebuilding or wrapping the same logic more than once.
There’s also the operational side. When you embed all the integration logic directly into your app, you’re responsible for managing credentials, handling retries, dealing with rate limits, and monitoring errors. That’s fine at a small scale, but once the number of APIs grows, the glue code can become brittle and hard to maintain.
Works best when…
– You need a fast MVP or demo.
– You are only connecting one or two APIs.
– Your team is comfortable managing auth, retries, and logging in-house.
Starts to hurt when…
– You must support multiple LLM hosts or providers.
– You need standardized cross-host discovery/schemas, and portable streaming & server-initiated messages.
– Governance and scaling across apps become critical.
Function calling
The next step many teams take is function calling. Instead of wiring APIs directly into your own backend, you define a set of functions (often in JSON Schema) and hand them to the LLM provider. The model then decides when and how to call them, filling in the arguments it believes are correct.
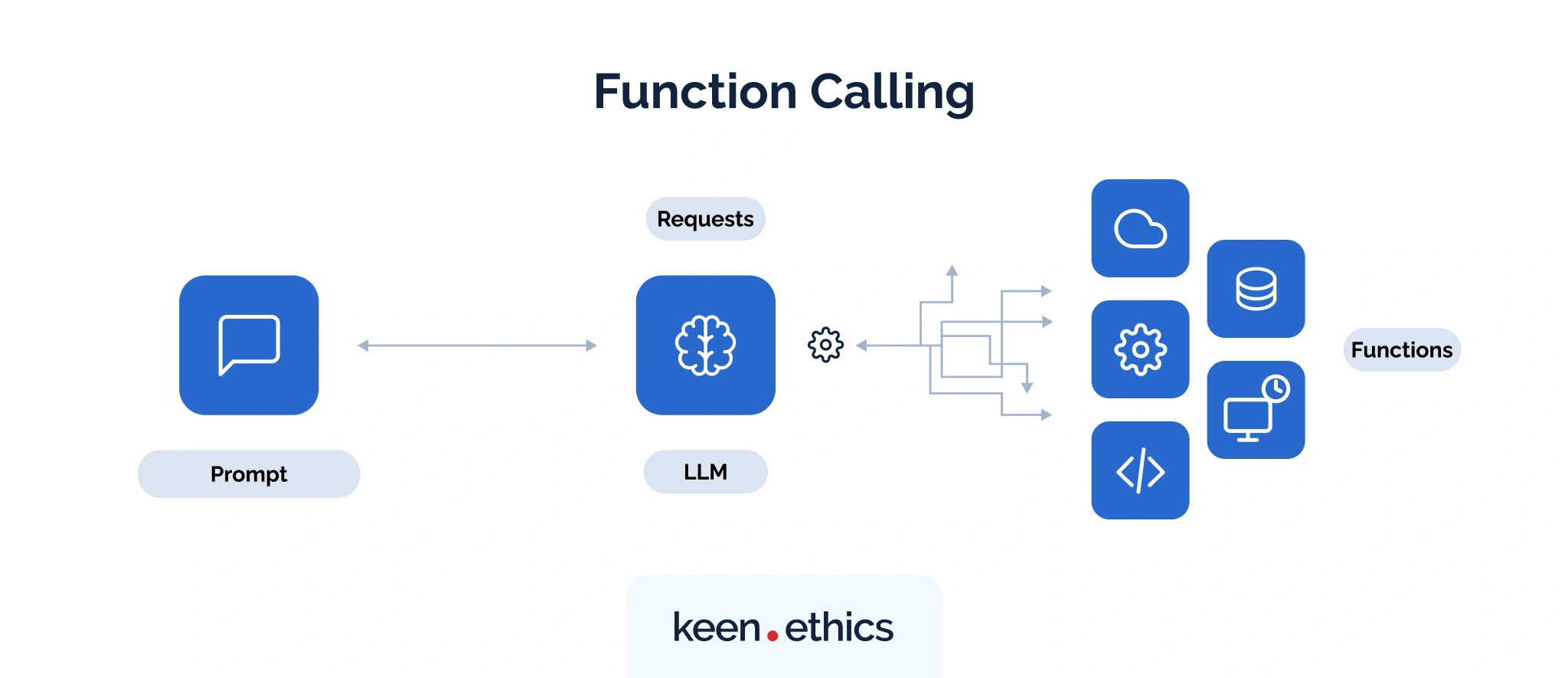
For example, OpenAI (through function calling) and Anthropic (through their tool use API) both allow you to define something like:

When a user types “Open a high-priority ticket for a login issue”, the model can respond with structured arguments — { “subject”: “login issue”, “priority”: “high” } — and the host executes the function.
For developers, this feels more powerful than raw API calls as it shifts some of the parsing burden onto the model. You don’t have to write brittle regexes to extract parameters, because the provider does the heavy lifting. It’s a natural fit when your app is anchored in a single LLM environment, like building a customer support chatbot on top of a provider’s native function-calling feature.
The limitations show up when you try to take the same integration elsewhere. Just as in the previous scenario, each provider defines its own schemas and invocation semantics. A function that works inside ChatGPT won’t run unchanged in Claude or another host. Streaming and progress updates are also handled differently across providers, so you often end up building custom glue code for each environment.
Works best when…
– You are building a tight integration for a single LLM provider.
– Tasks are narrow and well defined, such as book_meeting(start_time, attendees).
– You are comfortable relying on one provider’s function-calling semantics.
Starts to hurt when…
– You need the same functionality across multiple providers (e.g., ChatGPT and Claude).
– You need standardized streaming or progress updates for long-running tasks.
– You must enforce consistent security and auth across different environments.
Plugin systems
Then there are plugin systems, which are add-ons for a host app. They let third-party developers expose actions the model can call — e.g., “fetch a customer from the CRM.” The host environment handles discovery, permissions, and often provides a standardized UI so users can interact with the plugin safely.
Once teams want their models to do more than call a handful of APIs, they often turn to plugin systems. In this setup, you publish a plugin into a host environment, which then discovers your capability and surfaces it to users with UI and controls built in.
Such an approach has been popularized by ecosystems like ChatGPT, Wix, or integrations inside Slack and Notion. In each case, the host manages how capabilities appear and how they’re invoked, so you don’t have to build custom UIs or handle every request flow yourself.
By their nature, plugins offer a middle ground. You can package your capability and let the host handle the user experience. There’s no need to manually parse every model output or build custom UI from scratch, because the host provides standardized ways to display actions, forms, and results.
The challenges, however, surface around governance and control. Each host enforces its own rules for authentication, permissions, and distribution, which means you’re relying on someone else’s policies to protect sensitive data.
“Publicly available tools and resources must not expose or provide any way to retrieve sensitive information. Private tools should implement authentication and authorization to ensure a secure user experience.” — Alexander Shcherbatov, Keenethics developer
This dependency makes plugins great for adoption inside one ecosystem, but less flexible when you need consistency across many.
Works best when…
– Targeting a specific platform with built-in discovery (e.g., ChatGPT, Slack).
– Relying on host-provided UI for actions and forms.
– Quick adoption inside a live user base via an existing app.
Starts to hurt when…
– You must support the same capability across several plugin ecosystems.
– Plugin ecosystems evolve with different maintenance workflows.
– You need centralized auditing, rollout control, or consistent governance.
RAG pipelines
Another popular pattern is retrieval-augmented generation (RAG). In place of teaching a model everything in advance, you store your company’s knowledge — docs, FAQs, tickets, wiki pages — in a vector database, then retrieve the most relevant chunks at query time. Those passages are appended to the user’s prompt so the model can answer with fresher and more grounded information.
This method is practical because it builds on well-known components and doesn’t tie you to a single provider.
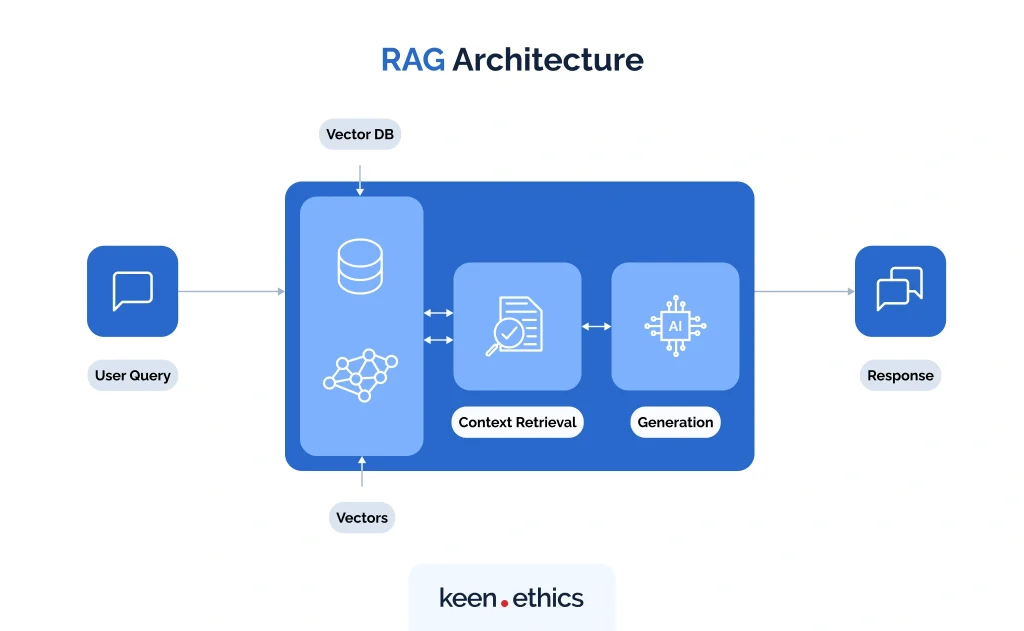
The limitations appear when you need more than static lookups. As one of our developers noted, RAG works best when the job ends at “find the right documents and ground the answer.” Once you want the agent to perform actions — creating tickets, updating files, running builds — you end up layering extra glue code or moving to MCP.
It is also worth noting that without a unifying protocol, every RAG setup ends up reinventing discovery, subscriptions, and permissions. Teams patch this with polling or custom webhooks, but that can make the system fragile over time.
Works best when…
– Answering questions from large, evolving knowledge bases (e.g., Confluence, Notion, SharePoint).
– Fresh information is more important than execution.
– You want to stay model-agnostic with minimal infrastructure.
Starts to hurt when…
– The assistant needs to perform actions, not just retrieve text.
– You need standardized streaming or progress updates.
– Multiple hosts must share the same knowledge source consistently.
MCP
The newest entrant is the Model Context Protocol, designed to standardize how models connect to tools and data across different hosts. An MCP server defines its capabilities — whether that’s a database query tool, a document resource, or a reusable prompt — through a JSON-RPC contract. Any compliant client, like ChatGPT, Claude, or even developer environments Replit and Zed, can automatically discover these capabilities and invoke them without extra adapters.
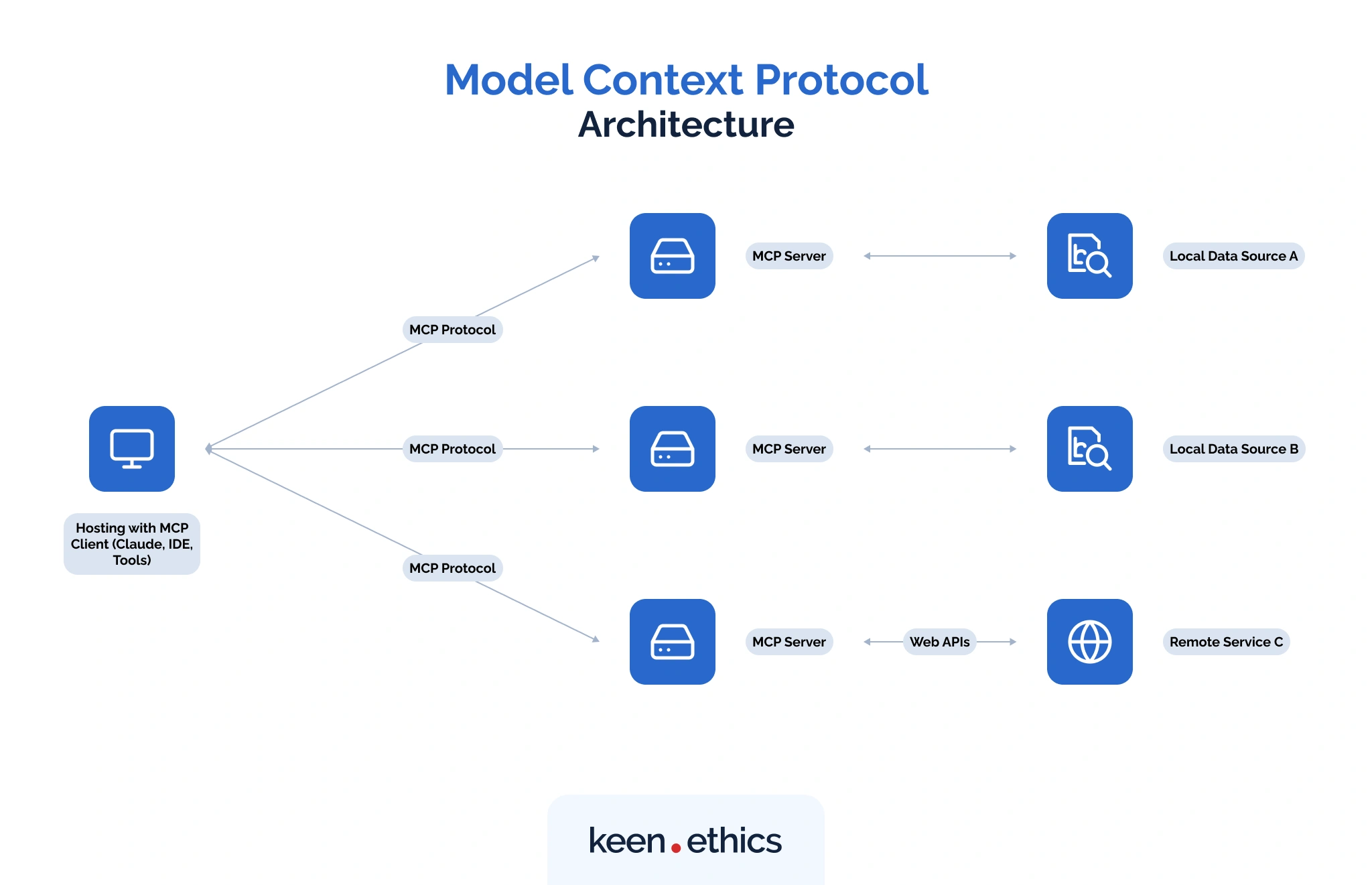
This model moves a lot of hidden work away from the application code. Authentication, authorization, and rate limiting can be centralized on the server. The transport layer is standardized through Streamable HTTP, which allows immediate application/json responses for quick tasks and text/event-stream for long-running jobs that need progress updates.
“MCP shines when cross-client reuse and long-running tasks with incremental feedback are required. It lets hosts discover and invoke the same Tools (actions) and access Resources (context) across IDEs, assistants, and agent runtimes, so one server integration works in many clients.” — Alexander Shcherbatov, Keenethics developer
Another strength is the idea of Roots, which defines the exact filesystem directories a server can touch. This prevents an LLM from wandering into sensitive parts of your infrastructure. Combined with standardized schemas (inputSchema, outputSchema) and automatic tool discovery (tools/list, resources/list, prompts/list), MCP provides a foundation that makes integrations safer and easier to reuse.
If you’re curious about the technical side of MCP, check out this article.
Works best when…
– You want one integration to work across multiple hosts (ChatGPT, Claude, Replit, Zed).
– Complex workflows need streaming updates, background tasks, or server-initiated requests.
– Centralized authentication, permissions, and auditing are priorities.
Starts to hurt when…
– You are building a quick prototype and don’t want to run extra infrastructure.
– You are locked into a single host and only need a handful of simple functions.
– Pure retrieval scenarios where RAG alone is enough.
Comparing the options in practice
As you can see, each LLM tooling option has evolved over time and brings its own set of benefits. Once we’ve covered the individual options, it’s time to look at how they stack up against each other in practice.
| Approach ㅤ | Complexity | Scalability | Flexibility | Cost |
| Direct API integrations | Low at first, but can grow as you build the API ↔ LLM layer ㅤ | Limited; every new API adds more glue code | Tied to one provider unless duplicated | Cheap at first, but maintenance costs rise as integrations grow |
| Function calling | Moderate; define JSON schemas per provider | Medium; good within a single ecosystem | Low portability – each provider has its own semantics | Efficient if you stay in one ecosystem, expensive if you must re-implement across hosts ㅤ |
| Plugin systems | Moderate; packaging and host review required | High inside one ecosystem, but siloed across hosts | Depends on host rules; UI and flows are fixed | Distribution is cheap once approved, but each host adds overhead ㅤ |
| RAG pipelines | Moderate; requires vector DB + orchestration | Scales well for retrieval workloads | Model-agnostic for knowledge lookups, but weak for actions | Infra costs (DB, hosting) can be high, but cheaper than retraining ㅤ |
| MCP | Higher upfront – requires running a server | High; supports streaming, reuse, centralized auth | Strong portability across clients, standardized discovery | Worth the overhead when governance and multi-host reuse matter |
Choosing the right approach for different scenarios
Sooner or later, every team will face the “what should we use?” question. The right answer depends less on hype and more on the constraints of your project: portability, scale, security, and how fast you need to move. Here are some concrete cases and what tends to work best.
Customer service copilot
When you’re targeting a single environment, a plugin system or native function calling is usually enough. You can describe a function in JSON Schema, let the model fill in arguments, and the host will handle UI and invocation. The challenge comes when support needs to span multiple hosts or when ticket handling requires consistent policies around data access. In those cases, MCP’s cross-client contract prevents you from rewriting the same functions in different formats.
Internal support agent
For an internal helpdesk bot that runs in just one environment, function calling is quick and reliable. It can safely handle simple actions such as reset_password(user_id) or open_ticket(issue). But once that agent needs to fetch files from a restricted directory or run a build that streams progress back, MCP becomes useful.
“With Streamable HTTP, a POST request can be answered with an SSE stream, letting the server push progress updates, partial results, and even server-initiated requests. This yields a responsive UX for builds, searches, and other multi-step operations.” — Alexander Shcherbatov, Keenethics developer
Knowledge-heavy assistant
If the task is about grounding answers in company documentation or research, retrieval-augmented generation is the natural choice. Vector search frameworks like Pinecone, Weaviate, or FAISS make it straightforward to index and query large datasets of text without retraining a model. Where MCP adds value is in structuring that context access.
By wrapping RAG inside a server that defines resources with stable URIs and listChanged notifications, teams can reuse the same knowledge base across clients and apply consistent permission policies.
Early-stage startup MVP
For early-stage teams, speed matters more than anything. It may seem natural to wire APIs into the backend, but in practice, building and maintaining that LLM-API layer can take more time. As our developer advises, it’s faster to define a few provider-specific functions that the model can call immediately, rather than designing a whole integration layer. In fact, many MVPs ship with nothing more than a handful of JSON-RPC functions, a minimal setup that proves the concept without delaying launch.
Enterprise automation
Enterprises with strict compliance rules rarely stay satisfied with ad hoc integrations. They need tight scoping of file access (via Roots), consistent authentication across multiple hosts, and auditable logs of every model action. MCP was designed with these requirements in mind, using centralized servers, standardized schemas, and Streamable HTTP for complex, long-running workflows. That makes it the most reliable choice when scaling beyond a single product or environment.
Finding the right fit
Answering the question “Is MCP the only solution?”, our honest response is no. Teams have a range of options, and each of them makes sense in different contexts depending on scope, scale, and priorities. A quick prototype may run faster on simple API calls, a single-platform assistant might thrive with native function calling, and knowledge-heavy use cases often lean on RAG.
Within this mix, MCP stands out because of how much ground it covers at once: portability across clients, built-in governance, structured context, and streaming for long-running tasks. That makes it especially compelling for businesses that are already thinking about scale and consistency.
In the end, you don’t have to adopt MCP just because it’s trending. What matters is choosing the approach that matches your project’s real needs. The ecosystem is still evolving rapidly, so the best move for any team is to stay adaptable and keep a close eye on how these standards develop.
Contact us to find out more about our software development services!